Google’s slow demise is entirely expected late-stage enshittification.
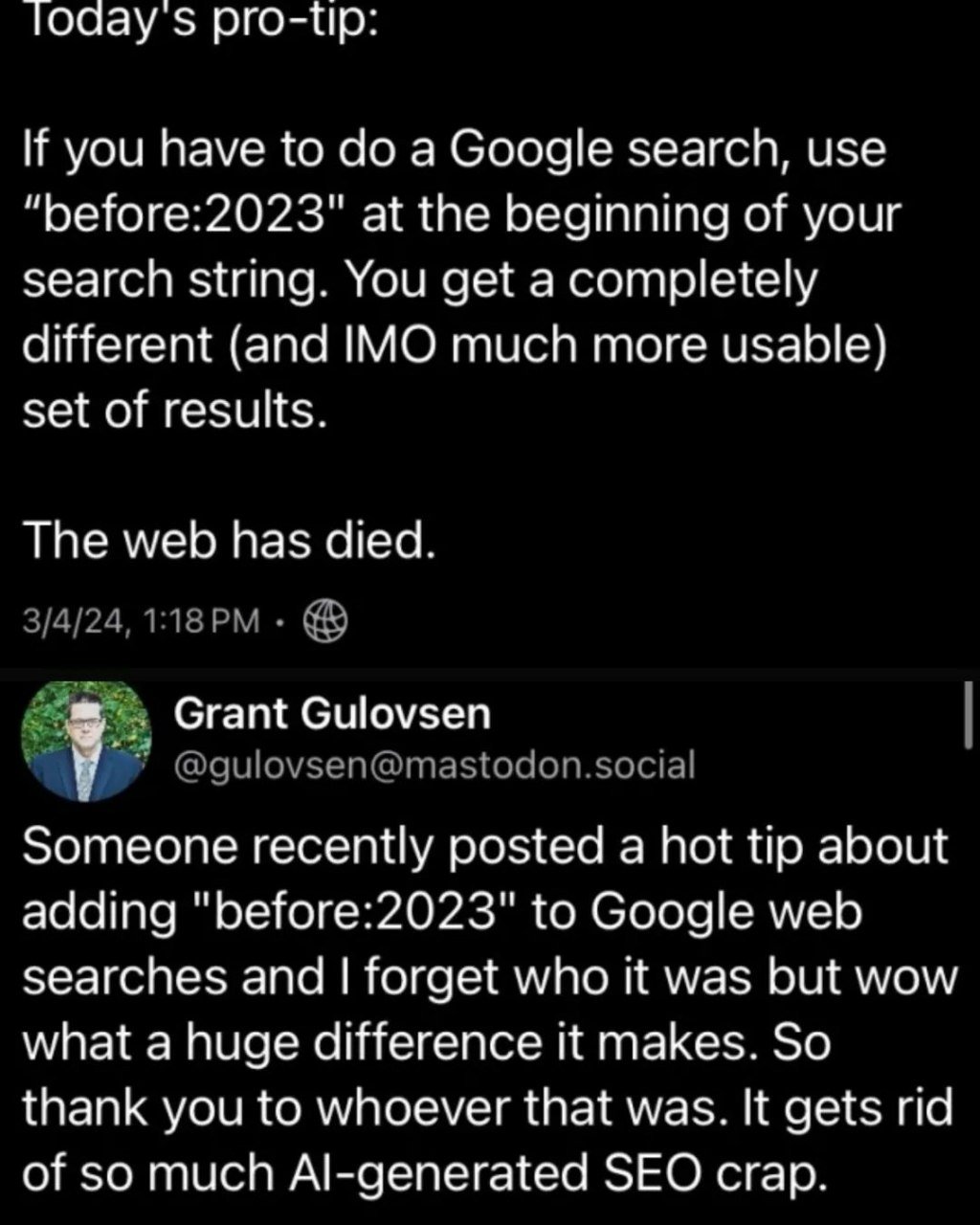
What is frustrating is that search is mostly a solved problem. Crawling and indexing are solved problems. Fighting adversarial SEO is a continuous task, that Google Search is essentially refusing to perform but is clearly cheap enough for an upstart like Kagi to do reasonably well (their only added-value is the aggregation and filtering of other indexers such as google and mojeek, and let’s be honest it’s probably 99% google’s index powering Kagi).
This shows that the lack of meaningful competition in the space is actually merely a matter of capital. There are too many webpages to scrape, process, and save and nothing short of “indexing almost as much stuff as google” is going to cut it.
In the software world we’re used to seeing FOSS alternatives to most things, because software’s capital costs are typically almost equal to manpower costs. However for search this doesn’t work, just like it historically hasn’t worked too well for some really expensive software (such as audiovisual creation tools, with the notable exceptions of Blender and to a lesser extent Krita).
There should be a well-funded non-profit building and providing a high-quality, exhaustive, transparent and open-source indexing service for the world. It definitely sounds possible, and even rather easy in the grand scheme of things. Yet current economic incentives do not favor such models. However I do wonder if there are not options to be explored, such as distributed crawlers or even a distributed index (after looking it up, YaCy seems to be doing just that though at a glance it seems, uh, old and clunky). Or maybe the EU should finally put a real focus on meaningfully funding indigenous FOSS R&D so the enshittification process of American tech giants doesn’t crush us as well.


{kind=link}
Google’s slow demise is entirely expected late-stage enshittification.
What is frustrating is that search is mostly a solved problem. Crawling and indexing are solved problems. Fighting adversarial SEO is a continuous task, that Google Search is essentially refusing to perform but is clearly cheap enough for an upstart like Kagi to do reasonably well (their only added-value is the aggregation and filtering of other indexers such as google and mojeek, and let’s be honest it’s probably 99% google’s index powering Kagi).
This shows that the lack of meaningful competition in the space is actually merely a matter of capital. There are too many webpages to scrape, process, and save and nothing short of “indexing almost as much stuff as google” is going to cut it.
In the software world we’re used to seeing FOSS alternatives to most things, because software’s capital costs are typically almost equal to manpower costs. However for search this doesn’t work, just like it historically hasn’t worked too well for some really expensive software (such as audiovisual creation tools, with the notable exceptions of Blender and to a lesser extent Krita).
There should be a well-funded non-profit building and providing a high-quality, exhaustive, transparent and open-source indexing service for the world. It definitely sounds possible, and even rather easy in the grand scheme of things. Yet current economic incentives do not favor such models. However I do wonder if there are not options to be explored, such as distributed crawlers or even a distributed index (after looking it up, YaCy seems to be doing just that though at a glance it seems, uh, old and clunky). Or maybe the EU should finally put a real focus on meaningfully funding indigenous FOSS R&D so the enshittification process of American tech giants doesn’t crush us as well.