
Copyright Sceptic
A twenty-something-year-old man with a knack for doodling, writing, piano playing, and wearing socks of questionable design.
My comments are not protected by copyright. Do what you want with them.
- 11 Posts
- 42 Comments


 39·11 months ago
39·11 months agoAh yes, I love memes about a foreign country’s politics!
The thread died prematurely, and nobody provided any sauce sadly
I have a pencil joke, but it has no point
“Parry this, Google and Facebook!”
Milorad Dodik (more like No-dick), even
 8·1 year ago
8·1 year agoI’m doing my part in opting out of copyright because fuck capitalism
I’d be publishing written works in the public domain but I like to be attributed, so copyleft will do for now, it’s catchy
Doesn’t look like it. The book is quite recent (2020)
What “rights” are there in the first place? This measure hurts the customer in the long run
There are a couple of files, actually.
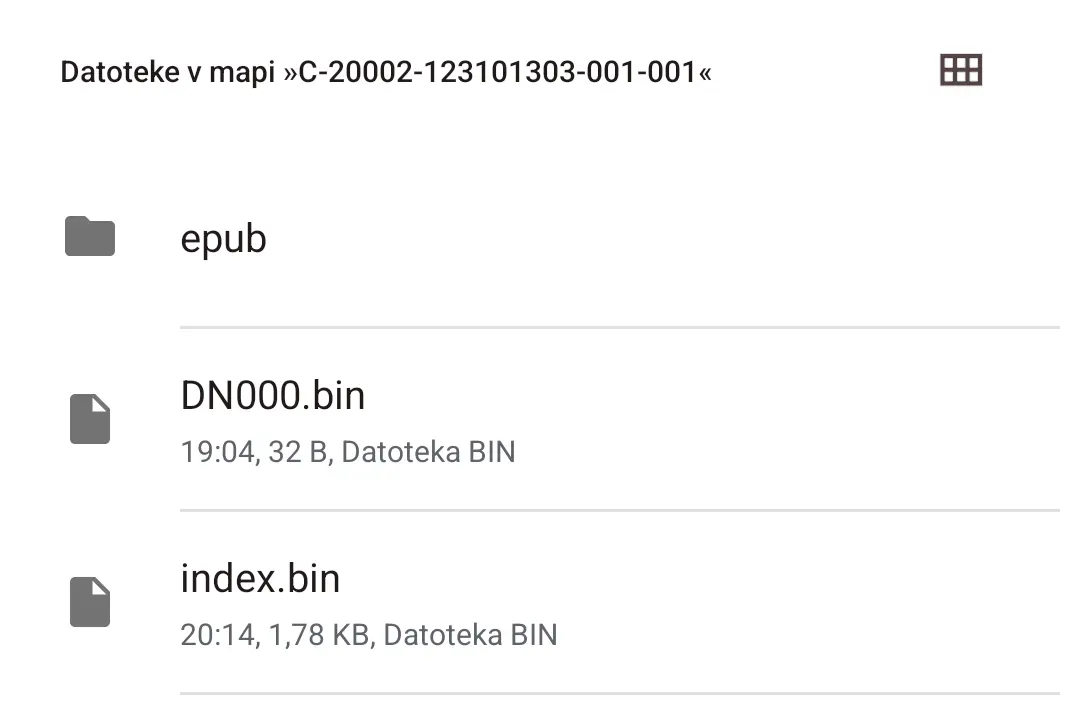

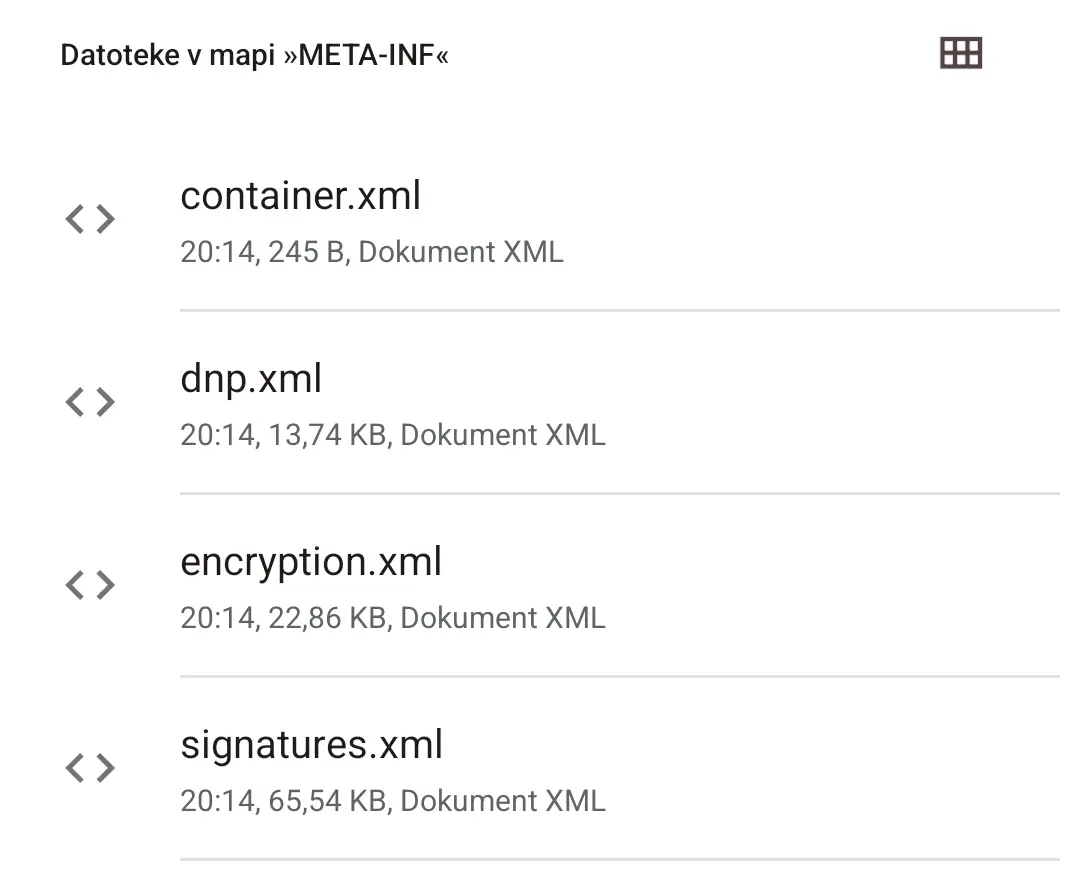
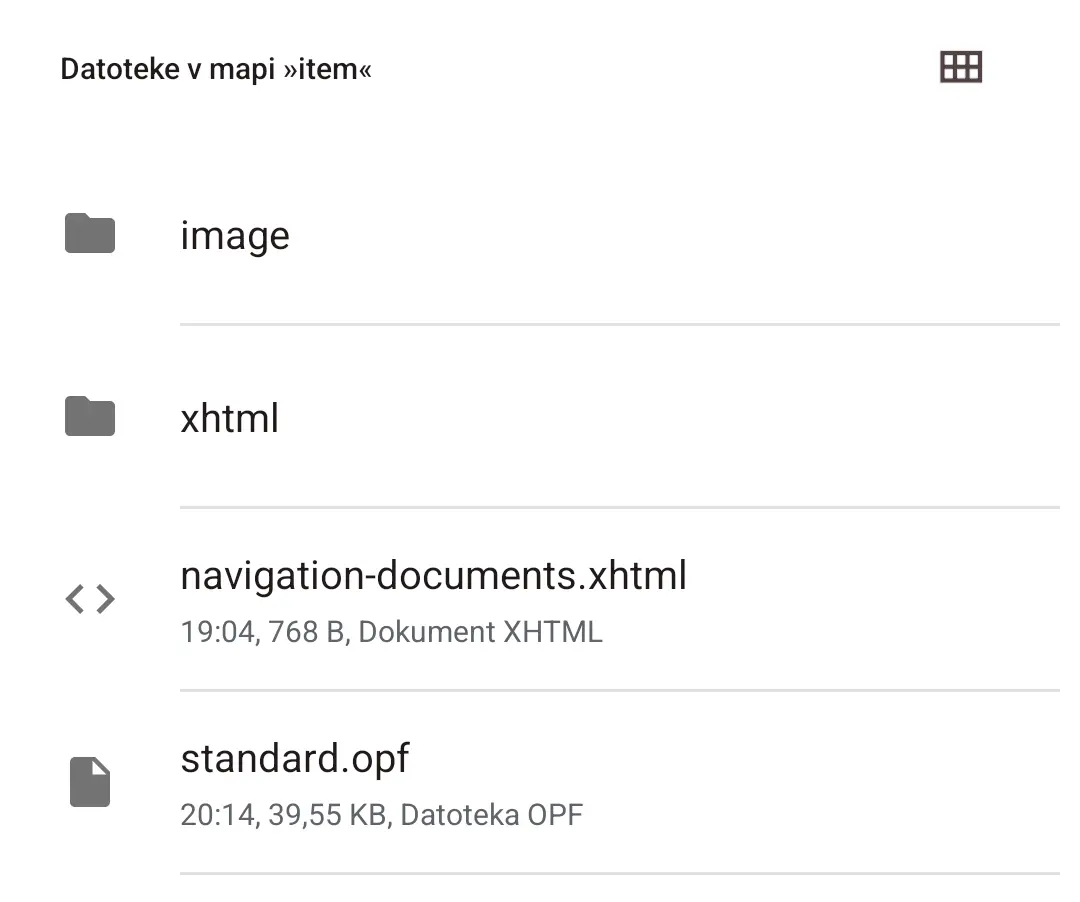
image and xhtml folders have the same amount of files (137), but the former has them in the jpg format, while the latter has them in the xhtml format.
Sorry for haphazardly explaining it like this, I’m on mobile.
Purina
So Nestlé, pretty much?
Obligatory Fuck Nestlé, btw
I don’t use Google Chrome anyway, so… phew
We still don’t know the secret behind Meghan Markle’s hair… besides deep hydration maybe
 11·1 year ago
11·1 year agoOh, nothing, it’s just me beginning to notice it. Nothing really happened
Yup, I’m thinking no bueno, chief
Unexpected? Well, it seems that way from the way I commented. I just want to find one example where something isn’t willingly protected under copyright law in Japan (it’s easier to find such media in the West than the East)
Perhaps I was. I recently started noticing it more and more, and I know it’s stupid but the same thing happened with registered trademarks
Actually… another cooming session won’t hurt, will it?
It’s fucking raw, so much so that it is still growing…

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I found an excruciatingly manual method of extracting comics which I purchased, but it works well
To make it a lot simpler, a Discord user made a script (with the help of AI) which takes the scrambled .jpg image and the tag (e.g. 3,4,7,14,0,13,12,11,6,10,2,8,15,5,1,9) and then uses ImageMagick to unscramble that image. Then I may have to edit the image manually (the edges for example are not scrambled so I have to edit those in)
I’d love to share the script with those who use Honto and would benefit from it, just gotta know if it’s alright with this community